
Morges, Suíça, 10 de janeiro.
Evgeny Bogdanov– GAMAYA, CTO.
À medida que a IA continua a penetrar em todos os setores, a agricultura está passando por uma transformação semelhante. Na Gamaya, estamos liderando esta revolução tecnológica, utilizando técnicas avançadas de IA para impulsionar o crescimento e a eficiência no setor de cana-de-açúcar em todo o mundo.
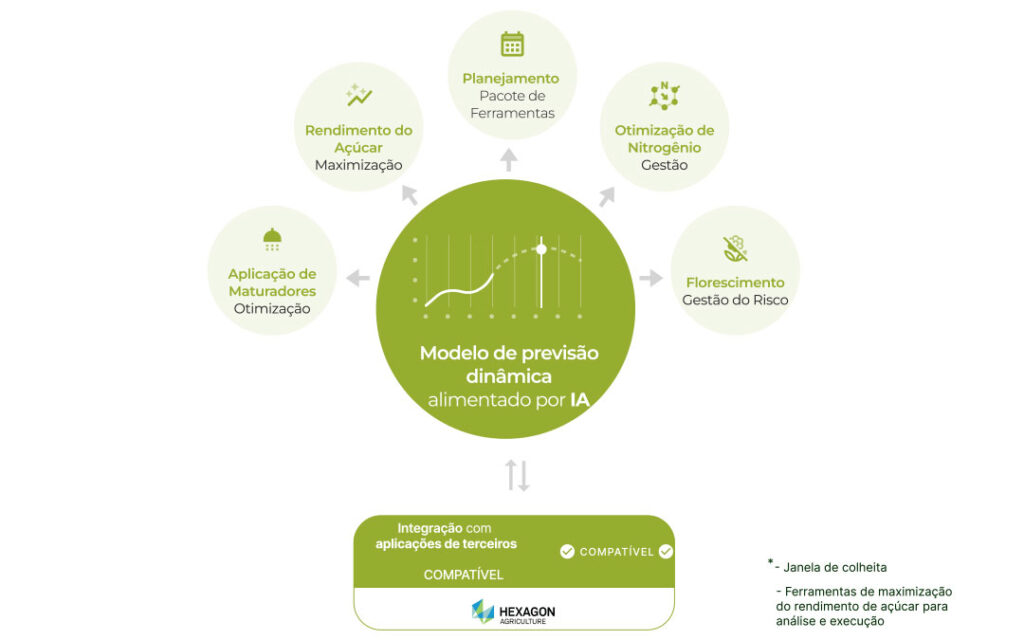
Nosso principal mecanismo para os produtores de cana-de-açúcar é o modelo de previsão, que prevê o desenvolvimento da cultura ao longo de todo o ciclo vegetativo. Essa capacidade é essencial para as usinas de cana-de-açúcar, pois previsões precisas permitem que elas tomem decisões operacionais importantes, incluindo planejamento orçamentário, decisões comerciais, otimização de operações de colheita, prevenção de riscos biológicos e otimização de aplicações de fertilizantes. A previsão precisa está diretamente ligada à produção de açúcar ou etanol, os principais KPIs do setor de cana-de-açúcar.

Nossos modelos de ciência de dados estimam o rendimento de biomassa e o teor de açúcar semanalmente para qualquer momento no futuro, permitindo que as usinas tomem as melhores decisões operacionais para melhorar o desempenho dos negócios e reduzir o teor de açúcar.
Jornada clássica do aprendizado de máquina: boa, mas não suficiente
Inicialmente, nossos modelos preditivos para rendimento de cana-de-açúcar e teor de açúcar foram desenvolvidos usando abordagens clássicas de aprendizado de máquina. Embora nossa análise de drones já utilizasse metodologias de deep learning, nossos modelos preditivos de conteúdo de rendimento e açúcar ainda estavam em seus estágios iniciais, com aquisição de dados em andamento ao longo de 2022. Para treinar nossos modelos, usamos inputs como clima, dados de sensoriamento remoto, atributos agronômicos de campo (variedade, data de plantio, etc.) e tipo de solo. Estes inputs são ajustados usando dados históricos de vários anos para fornecer as previsões mais precisas possíveis.
Nossos cientistas de dados conduziram um processo de engenharia de recursos, analisando várias fontes de dados para criar uma lista de recursos de entrada que têm a melhor correlação com o teor de açúcar e o rendimento. As características são muitas vezes inspiradas pelo conhecimento agronômico, e vários experimentos são conduzidos para determinar quais características são mais importantes para previsões melhores. Por exemplo, descobrimos que a área da curva de crescimento NDVI está altamente correlacionada com o rendimento da cana-de-açúcar (biomassa), fazendo com que a área ndvi se torne uma das características usadas em nosso modelo de previsão. No geral, utilizamos cerca de 150 características de inputs para treinar nossos modelos.
Embora o aprendizado de máquina clássico com engenharia de recursos tenha seus benefícios, ele também apresenta limitações e problemas. Embora nossos modelos clássicos de ML tenham fornecido bons resultados, encontramos rapidamente bloqueadores em que o modelo superestimou a previsão devido à maneira como os recursos de entrada foram projetados. Por exemplo, notamos que as previsões no meio da safra contaram com várias porcentagens acima das metas, um efeito que não estava presente no final da colheita. Essas questões nos levaram a experimentar técnicas de aprendizado profundo para melhorar ainda mais a precisão de nossos modelos.
Métodos de aprendizado profundo elevam o nível da acurácia
Quando começamos a explorar as abordagens de deep learning, já havíamos acumulado uma quantidade significativa de dados treinados. O aprendizado profundo não apenas nos ajudou a resolver o problema de superestimação, mas também melhorou drasticamente o desempenho geral do modelo. Nossa transição do aprendizado de máquina clássico para o aprendizado profundo nos permitiu aprimorar ainda mais nossos recursos de previsão, levando a um melhor suporte para as usinas de cana-de-açúcar e o setor agrícola como um todo.
E é assim que funciona
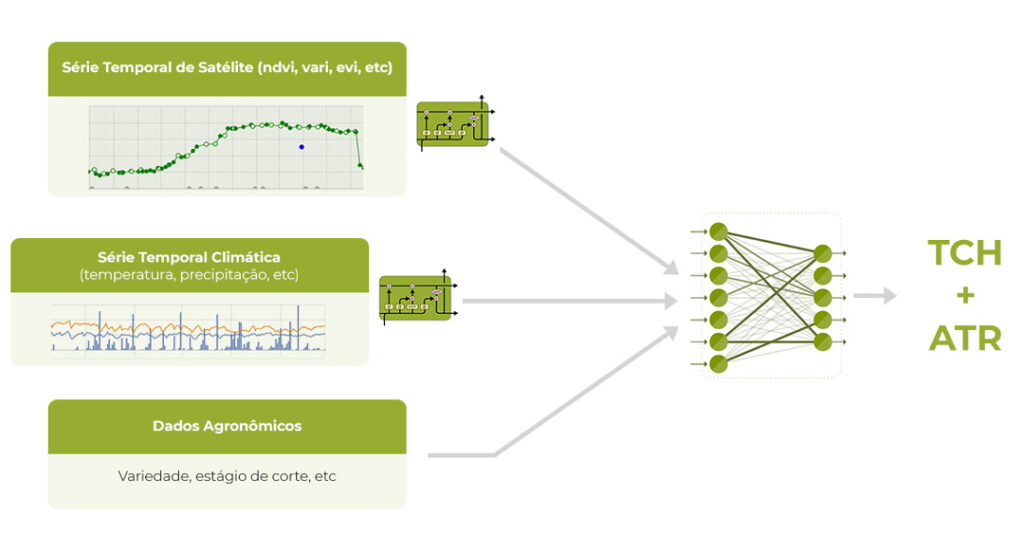
Para medir o desempenho de nossos modelos preditivos de rendimento e teor de açúcar, usamos duas métricas: erro a nível da usina e erro a nível do campo.
O erro a nível de usina é a quantidade média de biomassa (ton/ha) para toda a usina, que é um número altamente preciso e diretamente relacionado à biomassa total colhida por uma usina de cana-de-açúcar. O erro a nível de campo é o erro relativo médio medido em cada campo de cana-de-açúcar individual. Este número pode conter erros devido a erros manuais ou falta de dados registrados durante as operações de colheita.
Nossa abordagem de deep learning nos permitiu melhorar significativamente a precisão de nossos modelos preditivos de rendimento e teor de açúcar. Alcançamos métricas de precisão excepcionais de até 94% no nível de talhão e até 98% no nível de fazenda completa.
Além disso, nosso novo modelo de aprendizagem profunda (deep learning) resolveu o problema de superestimação, que era um problema significativo com nossa abordagem clássica de aprendizado de máquina, levando a uma melhoria na precisão geral. No entanto, acreditamos que podemos aprimorar ainda mais o desempenho de nossos modelos aproveitando novas fontes de dados, como resolução mais alta e imagens meteorológicas e de satélite mais frequentes, novos sensores e mais dados históricos.
Nossa equipe está atualmente realizando testes desses recursos de dados para melhorar a precisão de nossos modelos, que lidarão melhor com as variações climáticas sazonais.
Além disso, estamos trabalhando para extrapolar nossa experiência de modelagem para modelar mudanças no conteúdo orgânico do solo, o que é essencial para verificar programas de remoção de carbono no setor de cana-de-açúcar.
Na Gamaya, estamos comprometidos em revolucionar o setor agrícola, desenvolvendo e utilizando tecnologia de ponta para impulsionar o crescimento e a eficiência na produção de cana-de-açúcar. Nossos modelos de análise preditiva para rendimento de cana-de-açúcar e conteúdo de açúcar são apenas uma das muitas maneiras pelas quais estamos alcançando esse objetivo.





